📚
- Knowledge Representation and Reasoning
- Reinforcement Learning
- Software Engineering
- Visualization
- Science of Science
- Investment and Financial Planning
- Economic Development and Strategy
- Personal Finance
- Misc
- Seminar, Courses, Workshops, etc
Knowledge Representation and Reasoning
string2string: A Modern Python Library for String-to-String Algorithms
- https://github.com/stanfordnlp/string2string
- Hirschberg, Faiss
- PyPDF and PyPDFium2 tops the ranking as of August 2025.
Intelligent Document Processing Leaderboard
- Gemini Pro and Flash tops the ranking both in performance and cost as of August 2025.
- Most of the metrics rely on Levenshtein distance.
olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models
- “olmOCR-mix-0225, a collection of 260,000 crawled PDF pages paired with their OCR output by GPT-4o, that we use to train our models.”
- “fine-tune Qwen2-VL-7B-Instruct”
- “remove any document that failed to be parsed by pypdf, contains spam keywords, is a fillable form, or whose text is too short.”
- “GPT-4o does not produce sufficiently high-fidelity plain text on its own; for high-density pages or complex layouts, we found it is prone to omitting content, rewriting or completing content in a manner unfaithful to the original, or captioning images when not instructed to do so.”
- “document-anchoring indeed improves the output quality of GPT-4o”
- “operates by assessing a series of predefined pass-or-fail “unittests” … avoids use of soft metric (e.g., edit distance, ROUGE) comparisons against reference text which might fail to reveal fine-grained yet semantically important content extraction errors,” https://github.com/allenai/olmocr/blob/main/olmocr/bench/tests.py#L517
- 5,632 pages per dollar on H100 at 3,050 token per second.
On the Biology of a Large Language Model
- Stanford CS25: V5 I On the Biology of a Large Language Model, Josh Batson of Anthropic
- The middle layers of larger model has higher degree of generalization in multi-lingual tasks.
- Addition features are weird.
- There are “known answer” and “unknown answer” circuits that preceed refusal/inhibition.
- Current LLMs perform much better on reflection than a single pass will ever be able achieve w.r.t hallucination.
- “we expect that cross-layer transcoders are not the best long-term abstraction for understanding models, or at least are very incomplete.”
Tiny Model, Massive PDF Corpus: URL Embeddings for 8.3 Million PDFs
SAE (Scaling and evaluating sparse autoencoders) viewer
Generative Character-Level Language Models
xVal: A continuous number encoding for LLMs
Qwen3: Think Deeper, Act Faster
- Thinking vs non-thinking modes, which can be turned on or off on-demand in multi-turn conversation by adding
/thinkor/no_think - Support for 119 languages and Qwen3-32B achieves 73.0 on facebook/Multi-IF
- “Mistral 7B largely outperforms Llama 2 13B on all evaluations, except on knowledge benchmarks, where it is on par (this is likely due to its limited parameter count, which limits the amount of knowledge it can compress).”
- “Model leverages grouped-query attention (GQA) for faster inference, coupled with sliding window attention (SWA) to effectively handle sequences of arbitrary length with a
- reduced inference cost.”
- Many different Bert-based models for the Korean language: KorBERT, KoBERT, Kakao NLP Team, KoreanCharacter, KalBert, DistilKoBert.
- Korean is an agglutinative language. Using sub-character BidirectionalWordPiece tokenizer reduces [UNK] tokens dramatically and allows more precise tokenization.
Our book, Hands-On Large Language Models, Is Now Out!
- All code examples available on https://github.com/HandsOnLLM/Hands-On-Large-Language-Models
- For the interim reasoning mode, the RL steps use rule based verification to improve reasoning task performance without requiring significant amounts of labeled data.
- The interim model is used to generate quality RL training data where the interim model is trained on a smaller set of data and then a larger set of data is generated based on the model. Then, only the best labeled sets of the generated data is used for training the actual model itself.
XtremeDistilTransformers: Task Transfer for Task-agnostic Distillation
- Given a deep teacher and a shallow student, we align all the layers of the student to the topmost layers of the teacher
- We conjecture this to be an artifact of model capacity as it becomes increasingly difficult for a shallow student to mimic a much bigger and deeper teacher.
MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers
- Specifically, we propose distilling the self-attention module of the last Transformer layer of the teacher, which is effective and flexible for the student. Furthermore, we introduce the scaled dot-product between values in the self-attention module as the new deep self-attention knowledge, in addition to the attention distributions (i.e., the scaled dot-product of queries and keys) that have been used in existing works.
- Compared with previous approaches, using knowledge of the last Transformer layer rather than performing layer-to-layer knowledge distillation alleviates the difficulties in layer map- ping between the teacher and student models, and the layer number of our student model can be more flexible
- Using scaled dot-product between self- attention values also converts representations of different dimensions into relation matrices with the same dimensions without introducing additional parameters to transform stu- dent representations, allowing arbitrary hidden dimensions for the student mode
Parameter-Efficient LLM Finetuning With Low-Rank Adaptation (LoRA)
- finetuning a relatively large model such as LLaMA can be done in a few hours on a single GPU using LoRA
Automation of Summary Evaluation by the Pyramid Method
- There are O(n^2) + possible such sets for sentences of words; to avoid exponential runtime, we use a two-dimensional dynamic pro- graming algorithm, which selects the best contributor set for each span of words between the ith and jth words of a sentence, eventually producing a preferred covering for the entire sentence.
- The difference in correlation between the automatic Pyramid and the ROUGE scores is statistically significant (p 0.05) for all cases except the Pearson correlation between the automatic Pyramid (0.942) and ROUGE-1 recall score (0.805), which is not statistically significant (p = 0.129). We expect that more data will allow us to establish statistical significance for the remaining com- parison as well.
- Note that for ROUGE, as for our automatic evaluation, unigrams performs best, followed by the skip bigrams/unigrams combination, followed by the bi- grams. The differences among the ROUGE scores are considerable.
Evaluation of Text Generation: A Survey
- The Bilingual Evaluation Understudy (bleu) is one of the first metrics used to measure the similarity between two sentences (Papineni et al., 2002). Originally proposed for machine translation, it compares a candidate translation of text to one or more reference translations. bleu is a weighted geometric mean of n-gram precision scores.
- Caccia et al. (2018) found that generated text with perfect bleu scores was often grammatically correct but lacked semantic or global coherence, concluding that the generated text has poor information content.
- In Graham (2015), it was concluded that bleu achieves strongest correlation with human assessment, but does not significantly outperform the best-performing rouge vari- ant. A more recent study has demonstrated that n-gram matching scores such as bleu can be an insufficient and potentially less accurate metric for unsupervised language generation (Semeniuta et al., 2019).
- Recall-Oriented Understudy for Gisting Evaluation (rouge) (Lin, 2004) is a set of metrics for evaluating automatic summarization of long texts consisting of multiple sentences or paragraphs.
- rouge-l measures the longest matching sequence of words using longest common sub-sequence (LCS); rouge-s (less commonly used) measures skip-bigram15 -based co-occurrence statistics; rouge-su (less commonly used) measures skip-bigram and unigram-based co-occurrence statistics.
- Type-Token Ratio (ttr) is a measure of lexical diversity (Richards, 1987), mostly used in linguistics to determine the richness of a writer’s or speaker’s vocabulary. It is computed as the number of unique words (types) divided by the total number of words (tokens) in a given segment of language.
- The pyramid metric relies on manual human labeling effort, which makes it difficult to automate. peak: Pyramid Evaluation via Automated Knowledge Extraction (Yang et al., 2016) was presented as a fully automated variant of pyramid model, which can automatically assign the pyramid weights and was shown to correlate well with human judgments.
Reinforcement Learning
Mastering the game of Go with deep neural networks and tree search
Mastering the game of Go without human knowledge
Monte Carlo Tree Search: a review of recent modifications and applications
Language to Rewards for Robotic Skill Synthesis
DeepWalk: Online Learning of Social Representations
- Some graphs are created as a by-product of agents interacting with a sequence of elements (e.g. users’ navigation of pages on a website). When a graph is created by such a stream of non-random walks, we can use this process to feed the modeling phase directly. Graphs sampled in this way will not only capture information related to network structure, but also to the frequency at which paths are traversed.
Illustrating Reinforcement Learning from Human Feedback (RLHF)
- There are multiple methods for ranking the text. One method that has been successful is to have users compare generated text from two language models conditioned on the same prompt. By comparing model outputs in head-to-head matchups, an Elo system can be used to generate a ranking of the models and outputs relative to each-other. These different methods of ranking are normalized into a scalar reward signal for training.
- For example, the Fast Downward planner (Helmert 2006) uses Weighted A*, and LAMA (Richter and Westphal 2010) also uses a variant of Weighted A*.
- We first showed that greedy search can sometimes perform worse than A*, and that although in many domains there is a general trend where a larger weight in Weighted A* leads to a faster search, there are also domains where a larger weight leads to a slower search. It has long been understood that greedy search has no bounds on performance, but our work shows that poor behavior can occur in practice.
- The extended book [6] in Deep Blue is a mechanism that allows a large Grandmaster game database to influence and direct Deep Blue’s play in the absence of opening book information. The basic idea is to summarize the information available at each position of a 700,000 game database, and use the summary information to nudge Deep Blue in the consensus direction of chess opening theory.
- The specific mechanism used in Deep Blue was to assign bonuses (or penalties) to those moves in a given position that had been played in the Grandmaster game database. For example, suppose that in the opening position of a chess game the move d4 is given a 10 point bonus. Deep Blue would carry out its regular search, but offset the alpha-beta search window for d4 by 10 points. Thus d4 would be preferred if it was no more than 10 points worse than the best of the other moves.
Steps Toward Artificial Intelligence
- The problem of extinction or “unlearning” is especially critical for complex, hierarchical, learning.
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
- LLM+P takes in a natural language description of a planning problem, then returns a correct (or optimal) plan for solving that problem in natural language. LLM+P does so by first converting the language description into a file written in the planning domain definition language (PDDL), then leveraging classical planners to quickly find a solution, and then translating the found solution back into natural language.
- Without the context (i.e., an example problem and its corresponding problem PDDL), we observe that LLMs fail to produce correct problem PDDL files. The failures of LLM+P (no context) come entirely from incorrect problem encodings. Therefore, the context is important for LLM+P to work.
Software Engineering
My Thoughts on the Future of “AI”
Prophet: Automatic Forecasting Procedure
Building a Better Search Engine for Semantic Scholar
Stop Using dropDuplicates()! Here’s the Right Way to Remove Duplicates in PySpark
- Use Window.partitionBy
Lessons after a half-billion GPT tokens
Hosting SQLite databases on Github Pages
Using the SQLite-over-HTTP “hack” to make backend-less, offline-friendly apps
Visualization
Mapping thinkers: An interactive network visualization of the history of Western philosophy
Periodic Table of Visualization
SeeAlso - Wikipedia Visualizations
Science of Science
Themes in Academic Literature: Prejudice and Social Justice
Tweets to Citations: Unveiling the Impact of Social Media Influencers on AI Research Visibility
The complementary contributions of academia and industry to AI research
- Over the last 25 years, industry teams get more attention, are highly cited, and produce more state of the art models. Academic teams produce higher novelty work, unconventional and atypical. Robust control for subfield, team size, seniority, and prestige. Academic-industry collaboration is more similar to industry teams than academic teams.
- Academic-industry team does not bring the “best of the both worlds”
- The initial high impact of the academic-industry team might have been due to larger average team size and self-citation.
- In 2020, industry teams were 74% more likely to be highly cited than academic teams.
- Industry or academic-industry teams publish on interdisciplinary subfields, which is more likely to be cited by another field.
- In AI research, citations are correlated with state of the art models rather than novelty.
- Do the self and cross citations compare between teams or authors? In other words, if an industry team A cites industry team B, is that considered self citation within industry teams?
- Larger team size has more influence outlets and likelier to include researchers with different backgrounds.
- academic-industry team is bigger, then why is it doing worse?
- “We speculate that industry research is becoming increasingly more impactful and citation disruptive because they have more access to data, computational power, and people.”
- “AI field moves too fast”
- “Influence of these publications is not perceived through direct citations, but rather through network effects.”
Predicting the longevity of resources shared in scientific publications
- Most important factors are where and how the resource is shared. Author’s reputation or prestige of the journal does not play a considerable factor.
- Censored regression model, Random Forest, Wayback Machine API.
- About 90% of the URLs were alive. The mean life span is 19.45 years.
- Self-citation negatively correlates with lifespan. Length of the URL negatively correlates with maintainability. Presence of iframe tag negatively correlates with longevity.
The Impact of Heterogeneous Shared Leadership in Scientific Teams
- First authors do not fit the definition of scientific leadership.
- Combination of senior and junior leaders acn maximize team perforamnce compared to leaders of similar age.
- Paper citation is not a perfect metric for evaluating team performance.
Effects of Same-Race Mentorship Preferences on Academic Performance and Survival
- Increase in same-race mentorship prospensity over the years (last 70 years). It’s more pronounced for minorities. High same-race prospensity strongly correlates with lower productivity, impact, and collaboration reach, ultimately leading to 27.6% reduced linklihood of remaining in academia.
- Academic Family Tree project and the MAG.
Predicting scientific success
- academic-tree.org. Scopus. Linear regression with elastic net regularization.
Are AI Ethics Conferences Different and More Diverse Compared to Traditional Computer Science Conferences?
- MAG and Semantic Scholar. BERT-based gender and race prediction model.
- TFIDF + multinomial logistic regression to find predictive tokens.
- Asian countries lack publications of AIE conferences compared to NA and EU.
- AIE has more field diversity but less country diversity. AIE has lower male authorship but higher white authorship. h-index is insignificant.
International Workshop on Data-driven Science of Science
- “In a practical sense, science of science research can promote young scientists to establish their early career life, better evaluate the performance of scientific projects, track popular research frontiers, and even discover new questions from data.”
Is the future of peer review automated?
- “Automated screening tools cannot replace peer review, but may aid authors, reviewers, and editors in improving scientific papers.”
- ScreenIT pipeline has been used on bioRxiv and medRxiv preprints.
- Automated tools have the most potential to aid in assessing compliance.
- “Future work should enhance existing tools, simplify integration of tools into editorial systems, and train reviewers, editors and authors to use tool reports to improve papers. If successful, automated tools could reduce poor reporting and educate researchers about reporting best practices.”
Don’t judge a journal by its cover?: Appearance of a Journal’s website as predictor of blacklisted Open-Access status
- Appearance is a predictive factor of subpar journals (AUC of 0.736). Table of content, social media links and packed content are positive signs of good journals.
- Screenshot of 262 journals with 82 un-whitelisted.
Author-suggested reviewers rate manuscripts much more favorably: A cross-sectional analysis of the neuroscience section of PLOS ONE
- 8K manuscripts from 46K authors and 21K reviwers. author suggested review panel has 20% increase of acceptance compared to editor panels.
Damegender: Towards an International and Free Dataset about Name, Gender and Frequency
- The dataset is covering more than 20 countries in the occidental world reaching a big number of names and accuracies around (0.9%)
- Nowadays, many people are using APIs such as Genderapi, Genderize, Namsor, or NameApi. Other people are using solutions based on Wikipedia, or Free Software solutions (NLTK[LB02], R Gender, Gender Detector, Gender Computer3, …)
- BHKZ11, MLA+11 - Twitter
- WGJS15 - Wikipedia
- In [MS16] presents how to infer gender in Twitter. They are using namdict and the US census as datasets. The features are ’number of consonants’, ’number of vowels’, ’number of syllables’, ’number of bouba consonants’, ’number of bouba vowels’, ’number of kiki consonants’, ’number of kiki vowels’. The classification model is using SVM.
- [AWM+09] was presented as a system to classify name and ethnicity from Open Sources using Machine Learning extracting a name list from Wikipedia.
- ISO/IEC 5218 proposes a norm about coding gender: “0 as not know”, “1 as male”, “2 as female” and “9 as not applicable”
- The RFC 6350 (vCard) 5 where the section Gender has these categories: “m as male”, “f as female”, “o as other”, “n as not applicable” and “u as undefined”.
- Okay reading. Grammar mistakes. Mentions lots of datasets, but no pointers.
Damegender: Writing and Comparing Gender Detection Tools
- Before damegender, only Gender guesser2 offered a free software solution in this field [Kra06], and the project (i) has not been active for more than three years now, (ii) lies technologically well behind other solutions. The best contribution of Gender guesser is the dataset containing 48,528 names with a good classification by countries
- For instance, the Natural Language Tool Kit offers 8,000 labeled English names classified as male or female. Another example is Gender Guesser, which provides a good dataset for international names with different categories to define the probability. Although these datasets can be incorporated into damegender, the problem with them is that, in general, we have observed that they do not have the quality of National Statistics Institutes.
- Santamarıa and Mihaljevic [SM18] explain different ways to determine gender from a name; they offer 7,000 names that can serve as the golden set to evaluate them.
- The best results are given by Support Vector Machines and Random Forest – with those algorithms damegender achieves values that are close to more mature, proprietary solutions.
Comparison and benchmark of name-to-gender inference services
- We compare and benchmark five name-to-gender inference services by applying them to the classification of a test data set consisting of 7,076 manually labeled names.
- Another even simpler possibility to penalize non-classifications without giving them the same importance as to misclassifications is to minimize a metric such as errorCodedWithoutNA, which ignores the class ‘unknown’, while enforcing a constraint on naCoded, i.e., the rate of non-classifications
- For gender-guessers (not displayed) we have created one such parameter by setting it to 0.75 for responses ‘mostly_female’ or ‘mostly_male’ and 1 for ‘female’ or ‘male’.
- In each of the 10 runs of 10-fold cross-validation, Gender API produces the lowest error, NamSor the second lowest. In this scenario, it is possible to achieve an average inaccuracy rate under 9% over the whole data set while keeping the misclassification error under 5% with Gender API. NamSor and genderize.io achieve second place with average inaccuracy rates just under 15%.
- Python package gender-guesser achieves the lowest misclassification rate without parameter tuning for the entire data set, introducing also the smallest gender bias. At the same time it shows poor performance in terms of non-classifications, which is understandable given its comparatively small data base.
- Evaluation of name-based gender inference methods: https://github.com/GenderGapSTEM-PublicationAnalysis/name-gender-inference
Investment and Financial Planning
Do Stocks Outperform Treasury Bills?
- “Related, Lucca and Moench (2016) show that half of the excess return in US markets since 1980 accrues on the day before Federal Reserve Open Market Committee (FOMC) meetings.”
- The efficient-market counter argument is that Buffett may just have been lucky and, hence, many investors still wonder whether anyone has a chance to beat the market. Our findings suggest that Buffett’s success is neither luck nor magic, but reward for a successful implementation of value and quality exposures that have historically produced high returns.
- Sharpe ratio of 1 or 2 is unrealistic. Most investors should seek to achieve between 0.5 and 0.79.
The Financial Instability Hypothesis
- The first theorem of the financial instability hypothesis is that the economy has financing regimes under which it is stable, and financing regimes in which it is unstable. The second theorem of the financial instability hypothesis is that over periods of prolonged prosperity, the economy transits from financial relations that make for a stable system to financial relations that make for an unstable system.
- Furthermore, if an economy with a sizeable body of speculative financial units is in an inflationary state, and the authorities attempt to exorcise inflation by monetary constraint, then speculative units will become Ponzi units and the net worth of previously Ponzi units will quickly evaporate
Dividend Policy, Growth, and the Valuation of Shares
Explaining investor preference for cash dividends
Size Matters, If You Control Your Junk
International Diversification Works (Eventually)
- correlations across countries rise during bear markets.
- if you believe history is any guide to the future and invest in a single country for long enough, you should expect to experience a five-year period in which your real wealth is down 57 percent (equal-weighted)
- globally diversified portfolios are more negatively skewed than their local counterparts at short horizons (equal-weighted)
- Capweighted portfolios show little to no improvement as we extend the holding period.
- Our findings strongly support the hypothesis that long-term returns are primarily about a country’s economic performance and long-term economic performance varies across countries
Technological Revolutions and Stock Prices
Economic Development and Strategy
Sovereign Wealth Funds and Corporate Governance: A Minimalist Response to the New Mercantilism
The (Geo)Politics of Controlling Shareholders
- “developmental state capitalism, Chinese party-state capitalism, Russian oligarchic-klepto capitalism, and high-tech surveillance capitalism – each of which has produced distinctive, globally active firms with controlling shareholders. The activity of these firms has generated many thorny policy dilemmas, both for their home governments and foreign policymakers.”
Populists in Power: Economic and Political Consequences
- After the populist takeover, tariff, debt, and inflation increased.
- “The damage to democratic institutions may also explain why one populist is often followed by another and why populist governments often slip into authoritarianism and cling to power for a long time.”
- “serial populism”
- In 2019, Chinese immigrated to South Korea and Japan as much as Mexicans immigrated to the USA.
Personal Finance
Credit Cards
- Chase if under 5/24 else Amex.
- AUs add to your 5/24 count.
- Use churning.rankt.com for referrals.
- With Amex, once you ever have a “higher” card, you are ineligible for a “lower” card’s bonus.
- With credit history less than 1 year, Chase usually will not approve any cards.
- Chase URs, Amex MRs and Bilt points are tied for #1.
Income Tax
Digital Nomad Tax Questions Answered by a U.S. Tax Attorney
FEIE requires 330 days in a foreign country in a 12 month period. Self-employed person still have to pay self-employment tax (15.3%).
Some states such as California does not recognize FEIE.
Self Employment
Self Employment Tax Deduction
- If you pay self‐employment tax on your net earnings from self‐employment, you deduct one half of the tax as an adjustment to gross income, even if you do not itemize your other deductions
- The deduction for one‐half of your self‐employment tax is not a business expense, but a personal one. It does not reduce your profits on which you pay income taxes. The deduction reduces qualified business income for purposes of the QBI deduction (explained earlier in this chapter). If you opted to defer part of your 2020 self‐employment tax, 50% of the deferred amount must be paid by December 31, 2021; the other 50% is due by December 31, 2022.
First year expense
- To qualify for the election, your total equipment purchases for the year cannot exceed a set dollar amount. For 2021, you can claim the expensing deduction only if your total purchases are no more than $3,670,000. The dollar limit phases out on a dollar‐for‐dollar basis for total purchases over $2,620,000.
Retirement Planning
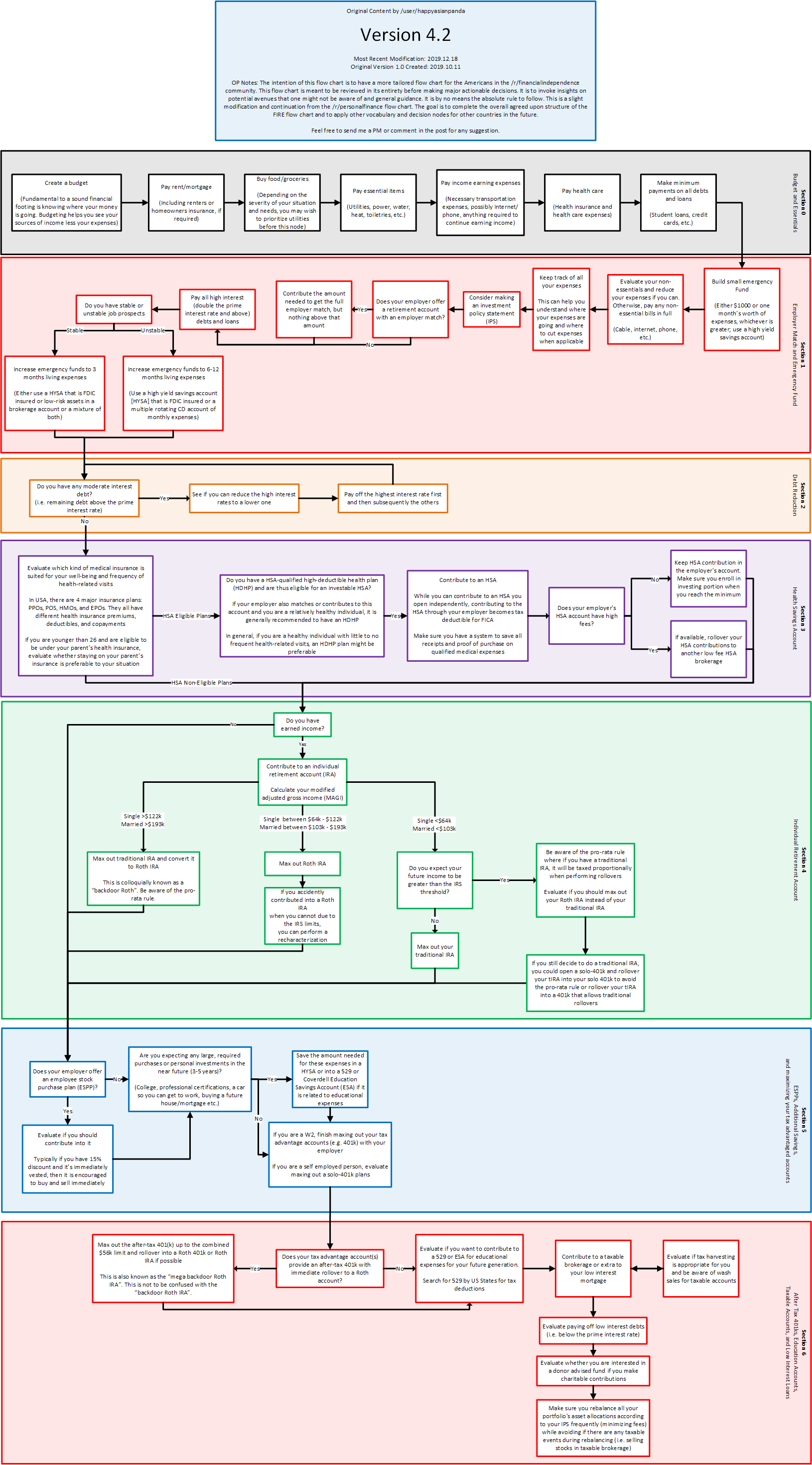{kind=link}
- 401K match -> HSA -> 401K max -> Traditional IRA -> Roth IRA
Brokerage
- Non-US investor’s guide to navigating US tax traps
- Avoid either/both US/non-US domiciled ETFs. They are taxed heavily due to PFIC. QEF election is complex.
- There are no unlimited marital exemption for NRA spouse ($60,000).
Solo 401K
- Employee contribution is fixed and adjusted based on inflation which is $23K for 2024. Employer contribution is up to 20% of salary up to $69K for 2024.
- Balance above 250K has an additional filing requirement.
- Solo 401(k) Contribution Calculator
Traditional 401K/IRA
- Some countries treat traditional IRA distributions as capital gains as if it was a taxable brokerage account.
Roth 401K/IRA
- Expat Roth Conversions Q&A
- Countries that regonized Roth are the followings: Belgium, Canada, Estonia, France, Latvia, Lithuania, Malta, United Kingdom, United States.
- Even if one is absolutely planning to retire in one of those countries, the complications from declaring and maintaining the Roth accounts will be non-negligible.
- Income from Roth could still count for the qualifying income or a portion of net-worth that affects health-care surcharge or a form of wealth tax, which would likely result in double taxation.
- Technically, US-France tax treaty does not mention Roth at all. In other words, it does not formally recognize the Roth.
- Most, like Belgium, do not tax the Roth IRA withdrawals but it still uses the income to calculate the tax rate one pays on other sources of income.
- The Great Roth Controversy
- Roth provides some flexibility around social security and Required Minimum Distribution (RMD). However, this requires about $10M in the tax deferred accounts.
- For the most common scenarios, a traditional retirement account is better than a brokerage account and both are better than a Roth IRA account.
- For Canada, CRA requires a one-time Treaty Election by including a letter detailing the Roth IRA account balance.
Health Savings Account
- HSA is touted as the “Tax Trifecta”. However, it is not recognized by any other country in the world. The yearly contribution is relatively small and it requires lifetime commitment to archiving medical receipts.
- Treated as a regular brokerage account, so it will be subject to capital gains tax and exit tax.
Social Security
- U.S. International Social Security Agreements
- How Early Retirement Affects Social Security
- 10 years (40 credits) to qualify for free Medicare Part A coverage at age 65 (which would otherwise cost $400+ per month).
- In 2016 it takes $1,260 of income to earn one credit (up to four credits maximum per year).
- Even if you don’t have the 40 credits, it might not matter since you can qualify on a spouse’s (or ex-spouse’s) record if they have the required 40 credits.
- By back-calculating things a bit, the lifetime earnings to max out that 90% payout space is $359,520 (for 2016). This could be $35,952 of earnings per year for ten years or roughly $72,000 for five years or around $18,000 for 20 years.
- Social Security Calculator
Non-resident Alien
- Europeans with us retirement plans
- If a non resident aliens withdraws from a 401k without a tax treaty, 30% withholding will be applied. Form 1040NR must be filed to claim the amount that was withheld due to the contributions being ECI.
- Even if one is covered by a tax treaty, a broker might not lower the withholding to 0%.
- US retirement accounts are always considered US Situs for the US Estate tax, which means that if you die holding more than 60k of assets in a US retirement account, you are looking at up to 40% tax on the account without an Estate tax treaty.
- Non-ECI is subject to 30% tax. (Non Effectively Connected Income: gains to a retirement account). EIC is subject to gradual tax bracket rates. (Effectively Connected Income: contributions to a retirement account).
- Forms 1040NR takes a long time to process (+6 months)
- Non-resident does not have access to the standard deduction.
Tax Treaties
Income Tax
- International taxation
- Most developed countries do tax foreign income of residents. United States is the only developed country that taxes foreign income of non-resident citizens.
- IRS - Tax Treaties
- IRS - United States Income Tax Treaties
- IRS - USA/France Tax Treaties
- US citizen or US permanent resident is to be US resident only if one has substantial presence in the US and/or one’s habitual abod is in the US.
- Pensions and other payments made under the social security legislation of France to a resident of France who is a citizen of the United States shall be taxable only in France.
- IRS - Tax Treaty Tables
Estate & Gift
- Utilizing Treaties to Eliminate or Reduce the Foreign Investor’s Exposure to the U.S. Estate Tax
- The US has estate tax treaties with Australia, Austria, Belgium, Denmark, Finland, France, Germany, Greece, Ireland, Italy, Japan, Netherland, Norway, South Africa, Switzerland, and the United Kingdom.
- The US has gift tax treaties (some of which are combined with the estate tax treaty) only with Australia, Austria, Denmark, France, Germany, Japan, and the United Kingdom.
- The US had an estate tax treaty with Canada. Although the U.S.-Canada estate tax treaty ceased to have effect with respect to estates of persons dying on or after January 1, 1985, a protocol in the U.S.-Canadian bilateral income tax treaty has far reaching effects upon Canadian individuals owning U.S. situs assets for U.S. estate tax purposes. (citation needed)
US-Canada
Income Tax
- US company cannot directly employee a Canadian tax resident.
- Income tax after deductions are paid to Canada, which is credited against US taxes via FTC. Or, income tax after deductions are paid to US, which is credited against Canada and the rest of the tax is paid to Canada.
- One must obtain the certificate of CPP coverage from Canada to be exempt from US FICA taxes
- There’s no married joint filing for Canada.
Retirement Planning
- Employee portion of 401K is not counted towards RRSP contribution limit. Only employer portion of 401K is counted.
- RRSP shares contribution limit with employer 401K contribution, which likely means that employer portion of the 401K contribution cannot exceed RRSP limit.
- Up to 31,560 for 2024 or 18% of previous year income. Contribution limit can be accrued and it can be withdrawn anytime.
- The contribution is not tax deductible in US and it requires FBAR filing because it is a foreign trust for US taxes. Some US states taxes interest income and capital gains from RRSP.
- US does not recognize TFSA.
- For non-residents of Canada, there’s a withholding of 25% for the lump sum withdrawal.
Incorporation in US
- Both LLC and S-Corp are not recognized in Canada and they are treated as foreign entities which would lead to double taxation. S-corp could avoid double taxation, but compliance is expensive.
Incorporation in Canada
- A corporation with a single contractor working for a single client in employer-employee like relationship is considered a Personal Service Business in Canada. This eliminates any benefit of incorporation in Canada. PSB applies to a client rather than the company as a whole. So, having multiple clients doesn’t prevent it.
Misc
Everyone Is Cheating Their Way Through College ChatGPT has unraveled the entire academic project.
- There are many Moomin books and the later ones are quite depressing.
- At some point, Moomintroll was killed off by one author and revived by another.
- It is found that in practice, digital nomadism is not always experienced as autonomous and free but is a way of living that requires high levels of discipline and self-discipline.
Seminar, Courses, Workshops, etc
MAS.S68: Generative AI for Constructive Communication Evaluation and New Research Methods